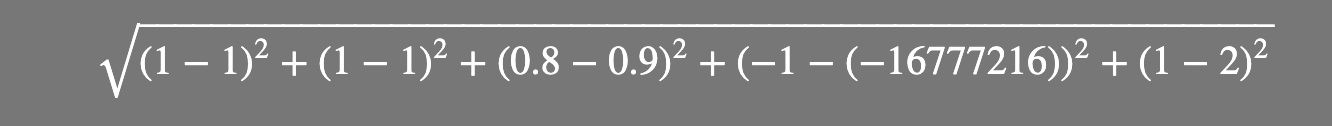Embedding是NLP中,用来表示一个词的常见的方式。不过,他的用途其实不仅仅可以用在NLP中,在简单的线性回归或逻辑回归中 ———— 进而在神经网络中,也可以使用到这个东西。
我当初在学习Embeding这个概念的时候,花了比较长一段时间才算真正理解。我不知道到底是这个概念本身理解起来就比较难,还是容易遗忘的原因。Anyway,因为这一点,我决定写一篇文章,说说我对Embedding的理解。
在回答什么叫Embedding之前,我们先提出一个问题:给定任意的两个东西,怎么样来衡量他们之间的相似性呢?
举个例子,比如说,牛奶、咖啡和苹果。通常意义下,可能大部分人都会认为“牛奶”和“咖啡”更相似,其他两对组合“牛奶”和“苹果”以及“咖啡”和“苹果”没那么相似。
如果要进一步问为什么,大家可能会说,“牛奶”和“咖啡”都是液体,都是可以喝的,都是常见饮料,都是装在杯子或瓶子里面的等等等等。也就是说,我们会想出某一些角度,或者说一些特征,来衡量他们的相似性。这些“角度”或者说“特征”,我们用稍微显得专业一点的词来说,叫做维度。
如果我们把主要考虑的几个维度简单的列一下,可能会得出以下的一些:
是否食物、是否液体、是否需要人为加工、颜色、味道等等。列出这些维度以后,我们可以给这三个考察对象的每一个维度都分别“打个分”,分配一个数值。如下:
| 是否食物 | 是否液体 | 人为加工 | 颜色 | 味道 | |
|---|---|---|---|---|---|
| 牛奶 | 1 | 1 | 0.8 | -1 | 1 |
| 咖啡 | 1 | 1 | 0.9 | -16777216 | 2 |
| 苹果 | 1 | 0.2 | 0.1 | -16711936 | 3 |
你可能会有疑问,是否食物、是否液体、是否人为加工的数值都是小数,可以理解为“在多大程度上是食物/液体/人为加工”,但是颜色和味道的值怎么理解呢?
在上面的表格中,颜色的值我取得是Java中Color类的WHITE、BLACK、GREEN三个常量的数值。味道的三个值是我随便取得,你可以理解为,我们可以把每一种味道都用一个数字来表示,然后1、2、3分别是代表牛奶、咖啡、苹果的味道的数字。不用过分纠结这里的数字具体是什么值,这里只是举例说明一下原理。
好了,现在我们确定好了这些“维度”,并且给我们的考察对象在每一个维度上面都打了分,那么我们就可以用一个向量来代表我们的一个考察对象了。比如:
- 牛奶:[1, 1, 0.8, -1, 1]
- 咖啡:[1, 1, 0.9, -16777216 , 2]
- 苹果:[1, 0.2, 0.1, -16711936, 3]
每个对象对应的向量,就是表格中对应的那一行。这里的向量,其实就叫一个Embedding。如果要用稍微正式的语言来陈述一下,那就是:一个Embedding,就是用于描述某个实体的一个向量,这个向量里面的每一个值代表这个实体在某个维度上面的“打分”。
在实际使用的过程中,Embedding的生成过程可能跟我们上面讲述的过程不大一样。我们先来看一下PyTorch里面,Embedding的使用是怎么样的。
>>> import torch
>>>
>>> e = torch.nn.Embedding(3, 5)
>>> e
Embedding(3, 5)
在上面的例子中,使用torch.nn.Embedding(3, 5) 创建了一个Embedding,其中需要两个构造参数3和5。这两个参数分别是什么意思呢?
“3” 是表示我们的“实体”有多少个。“5” 则是我们用来考察这些实体的维度有多少个。
在真正构建深度学习模型的时候,我们不可能把“牛奶、咖啡、苹果”等这些东西使用字符串的形式表示,而是需要使用某种方式来把他们“数字化”。最简单的,就是使用一个含有三个元素的一维向量。在这个向量中,只有一个元素的值是1,其他都是0。不同位置上的1代表不同的实体。比如:
- 牛奶:[1, 0, 0]
- 咖啡:[0, 1, 0]
- 苹果:[0, 0, 1]
这种用一维向量来表示所有实体的方式叫做 one-hot encoding。
现在,回头来看,Embedding的两个参数,第一个是用来表示某个实体的“one-hot encoding”的向量的元素个数。第二个参数就是用于考察这些实体的不同维度的个数。
也就是说,在真正使用的过程中,Embedding一般是结合实体的表达方式“one-hot encoding” 一起使用,这是第一点需要注意的。
第二点需要注意的是,Embedding的特征维度(Embedding的第二个参数)的确定过程,跟我们上面讲述的例子也不一样。在我们上面的例子中,Embedding的特征维度个数是这样确定的:首先,人为选定了一些特征,比如是否食物、是否液体、人为加工、颜色、味道。然后,清点一下特征的个数,由此确定,是5。
然而在真正使用Embedding来训练深度学习模型的时候,我们其实只是根据自己的经验,选定一个数,比如5,或7,然而这个5或7具体代表哪些特征,其实是不知道的。因此,代表某一个实体的Embedding 向量,比如:
苹果: [ 1, 0.2, 0.1, -16711936, 3]
这里面的每一个元素代表什么含义,其实是未知的。
至于这个数值到底应该选定为多少,这个是“调参师”应该去关心的问题了。
而向量里面的每一个元素的具体取值,也不是人为的去给定,而是模型在训练的过程中,会去自动的调节的。其实所谓的训练模型,说白了,就是在调整这些值而已。
好了,讲到这里,相信你已经明白Embedding的概念了。最后,我们来回答一下文章开头提出的问题。那就是,如何来衡量任意两个东西之间的相似性呢?有了Embedding,这个问题就很好回答了。任何两个东西的相似性,都可以用表示这两个东西的Embedding向量之间的“距离”来衡量:
- 牛奶:[1, 1, 0.8, -1, 1]
- 咖啡:[1, 1, 0.9, -16777216 , 2]
那么,牛奶和咖啡的相似性 =